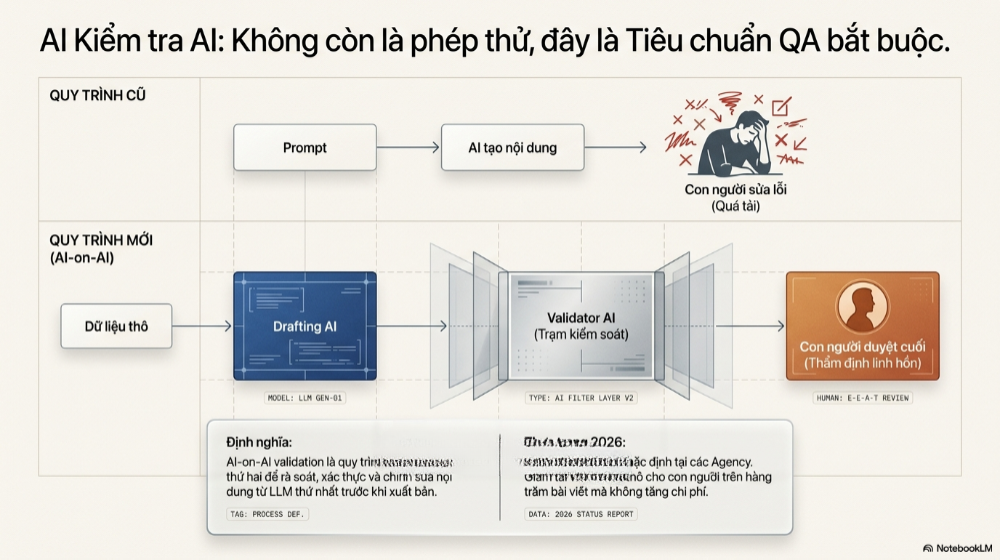
AI kiểm tra nội dung của AI (AI-on-AI validation). Đây là quy trình mà trong đó một mô hình ngôn ngữ thứ hai được giao nhiệm vụ rà soát, xác thực và chỉnh sửa lại nội dung do một mô hình ngôn ngữ thứ nhất tạo ra, trước khi văn bản đó được công bố ra công chúng. Đây không còn là một thử nghiệm ngẫu hứng của vài người làm content chuyên sâu – nó đang trở thành một lớp lọc bắt buộc, gần như một quy trình kiểm soát chất lượng (QA) tiêu chuẩn trong dây chuyền sản xuất nội dung quy mô lớn năm 2026.
Lý do bộ lọc này trở nên bắt buộc rất đơn giản: bản dự thảo đầu tiên từ một AI, dù được tạo ra bởi mô hình mạnh nhất, vẫn mang theo những lỗ hổng mang tính hệ thống, từ việc bịa đặt thông tin một cách tự tin (hallucination), đến cấu trúc câu rập khuôn dễ bị các thuật toán xếp hạng và cả người đọc tinh ý nhận ra ngay từ cái nhìn đầu tiên.
Khi một AI khác đóng vai trò "biên tập viên", nó không thay thế con người, mà đóng vai trò một tầng lọc trung gian, giảm thiểu phần việc thô của quá trình hậu kiểm trước khi con người đưa ra quyết định cuối cùng.
Hiện tượng này đang định hình lại cách các agency, các nhà sáng tạo nội dung độc lập và cả các tòa soạn vận hành quy trình biên tập – nơi mà "biên tập viên" không còn chỉ là một con người ngồi đọc và sửa câu, mà là một chuỗi các mô hình AI được xếp lớp lên nhau, mỗi lớp đảm nhiệm một nhiệm vụ kiểm định riêng biệt.
Bản chất của vòng lặp "AI-on-AI" và sự trỗi dậy của "Biên tập viên thuật toán"
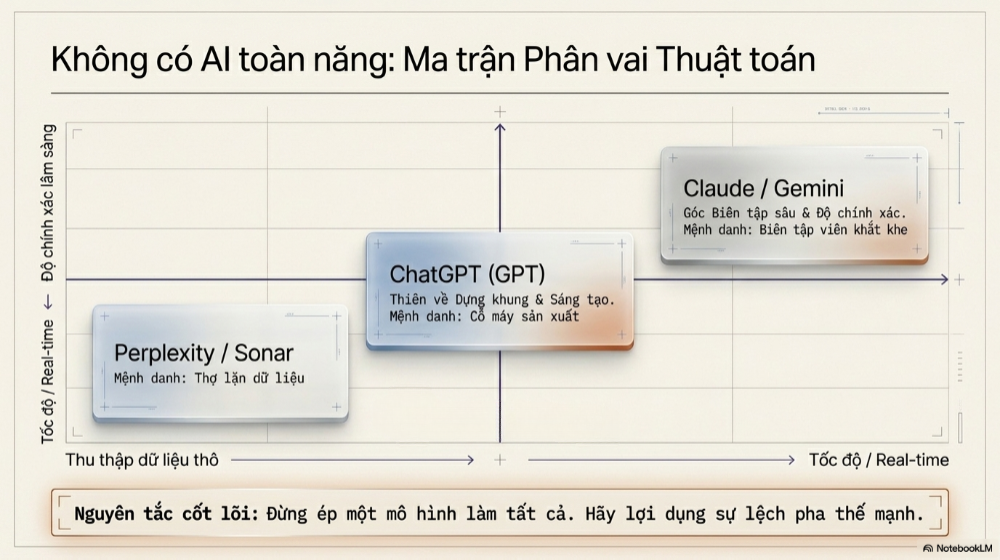
Thực trạng phổ biến nhất hiện nay trong giới sản xuất nội dung diễn ra theo một mô-típ khá nhất quán: người dùng giao cho một mô hình thiên về tốc độ và khả năng tìm kiếm – ví dụ ChatGPT hoặc Perplexity – nhiệm vụ tạo ra bản dự thảo sơ khởi, gom nhặt dữ kiện, dựng khung sườn ý tưởng. Sau đó, chính bản dự thảo đó được đưa qua một mô hình thứ hai, thường được lựa chọn vì khả năng suy luận và xử lý ngôn ngữ tinh tế hơn, như Claude hoặc Gemini để đóng vai trò lớp kiểm định (Validator), rà soát lại toàn bộ nội dung trước khi xuất bản.
Sự bùng nổ của mô-típ này không phải ngẫu nhiên. Nó xuất phát từ một nhận thức ngày càng rõ ràng trong giới Content Creator và Agency: một mô hình AI đơn lẻ, dù mạnh đến đâu, vẫn có "điểm mù" riêng của nó, và điểm mù của mô hình A thường lại chính là điểm mạnh của mô hình B. Một nghiên cứu công bố giữa năm 2026, phân tích trên gần 480 triệu kết quả đầu ra AI trong các lĩnh vực pháp lý, tài chính và y tế, cho thấy việc bổ sung một lớp xác minh chéo từ mô hình thứ hai đã kéo tỷ lệ sai sót thông tin từ mức 8,3% xuống chỉ còn 3,2% – tương đương mức giảm 61% số lỗi sai lệch dữ kiện so với khi chỉ dùng một mô hình duy nhất.
Với giới Agency vận hành nội dung ở quy mô lớn, nơi một biên tập viên con người không thể nào đọc kỹ từng câu trong hàng trăm bài viết được sản xuất mỗi tuần. Việc dựng một "trạm kiểm soát" bằng AI thứ hai trở thành lựa chọn kinh tế gần như tất yếu. Nó không tốn thêm nhân sự, không kéo dài lịch xuất bản, nhưng vẫn tạo ra một lớp phòng vệ trước khi nội dung chạm đến tay biên tập viên con người cuối cùng (nếu có).
Từ đây, một danh xưng mới dần được giới chuyên môn sử dụng: "Biên tập viên thuật toán" – không phải một con người, mà là một quy trình do máy vận hành, có vai trò tương đương với vị trí Sub-editor trong một tòa soạn truyền thống: không sáng tạo nội dung gốc, nhưng có quyền cắt, sửa, và đôi khi viết lại hoàn toàn một đoạn văn trước khi nó được phép "lên trang".
Tại sao chúng ta không thể tin hoàn toàn vào nội dung đầu tiên của AI?
Để hiểu vì sao lớp kiểm định thứ hai trở nên cần thiết đến vậy, cần nhìn thẳng vào ba lỗ hổng mang tính hệ thống mà gần như mọi mô hình ngôn ngữ hiện nay đều mắc phải ở một mức độ nào đó.
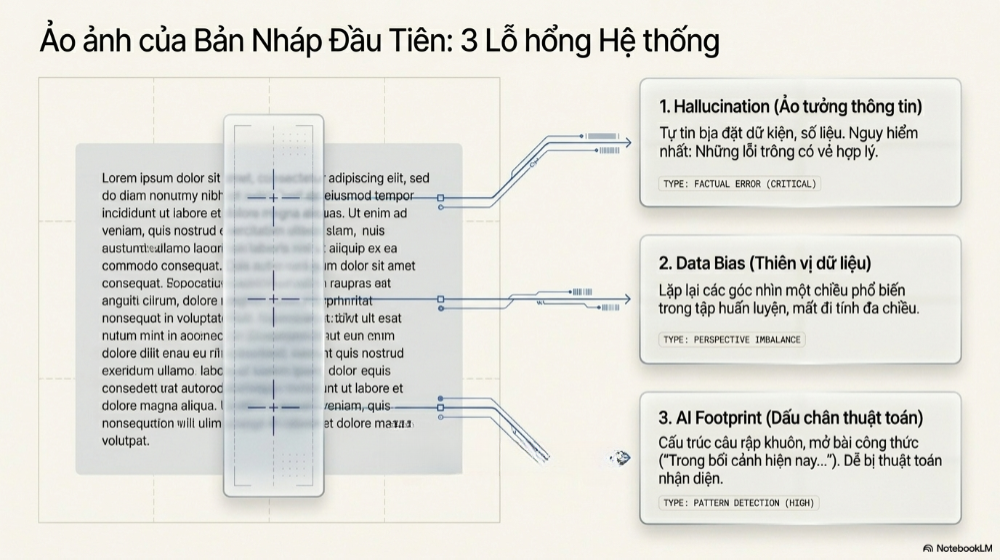
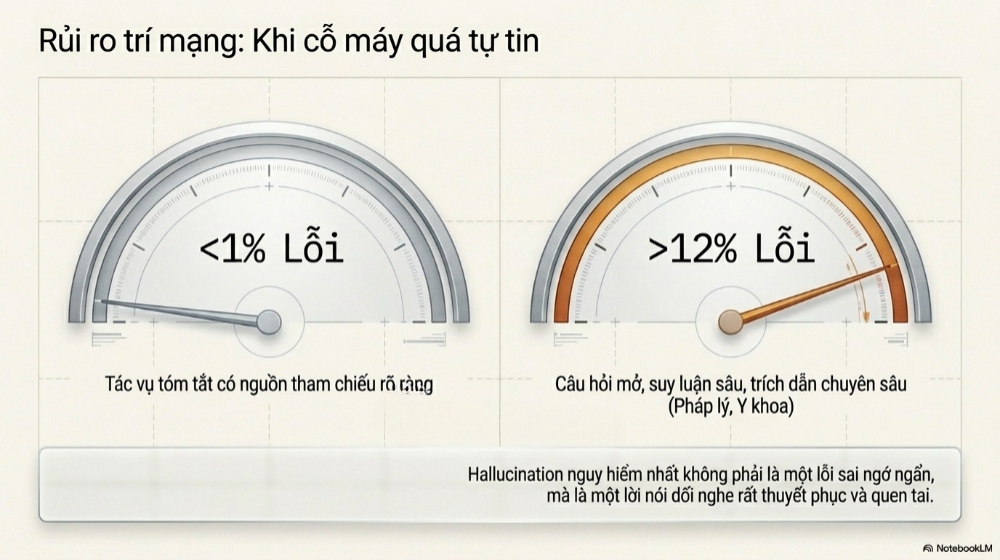
Thứ nhất là ảo tưởng thông tin (Hallucination) – hiện tượng mô hình AI tự tin bịa ra một dữ kiện, một con số, hay một trích dẫn không hề tồn tại, nhưng trình bày với giọng văn chắc chắn không khác gì một sự thật đã được kiểm chứng. Mức độ nghiêm trọng của vấn đề này thay đổi rất lớn tùy theo loại tác vụ: trên các bài toán tóm tắt có nguồn tham chiếu rõ ràng, những mô hình hàng đầu năm 2026 đã giảm tỷ lệ sai sót xuống dưới 1%, nhưng với các câu hỏi mở, yêu cầu suy luận sâu hoặc trích dẫn nguồn cụ thể, tỷ lệ này có thể vọt lên đến hơn 12%, thậm chí cao hơn nhiều ở những lĩnh vực chuyên sâu như pháp lý hay y khoa.
Điều đáng lo hơn cả: hallucination nguy hiểm nhất không phải là lỗi sai rõ ràng, mà là loại lỗi "trông có vẻ hợp lý", một con số nghe rất thuyết phục, một trích dẫn nghe rất quen tai, nhưng hoàn toàn không có thật.
Thứ hai là sự thiên vị dữ liệu (Data Bias) – mô hình AI học từ một tập dữ liệu khổng lồ nhưng không trung lập, dẫn đến xu hướng lặp lại các góc nhìn, ví dụ, hoặc khung phân tích phổ biến nhất trong dữ liệu huấn luyện, thay vì phản ánh đầy đủ tính đa chiều của một vấn đề. Với nội dung mang tính phân tích hoặc đưa ra khuyến nghị, thiên vị này có thể khiến bài viết trở nên một chiều mà cả người viết ban đầu (AI) và đôi khi cả người đọc cũng không nhận ra.
Thứ ba, và có lẽ dễ nhận diện nhất với người đọc thông thường, là cấu trúc câu rập khuôn, thứ mà giới chuyên môn gọi là "AI Footprint". Đây là tập hợp các cụm từ, cách mở đoạn, cách chuyển ý mà các mô hình AI có xu hướng lặp lại một cách máy móc đến mức trở thành "dấu vân tay" dễ nhận ra của văn bản máy tạo ra.

Tuy nhiên, cần làm rõ một điểm dễ bị hiểu nhầm: bản thân việc văn bản "có dấu vết AI" không tự động khiến nó bị các công cụ tìm kiếm như Google hạ bậc. Theo các hướng dẫn cập nhật của Google về nội dung tự động hóa, hệ thống xếp hạng không trừng phạt nội dung chỉ vì nó được AI tạo ra, mà nó trừng phạt nội dung kém chất lượng, thiếu tính nguyên bản, được sản xuất ồ ạt mà không mang lại giá trị thực sự cho người đọc, bất kể nội dung đó do người hay máy viết ra.
Bộ hướng dẫn đánh giá chất lượng tìm kiếm (Search Quality Rater Guidelines) của Google thậm chí còn nêu rõ: nội dung được sao chép, diễn giải lại hoặc tạo tự động với rất ít công sức, tính nguyên bản hoặc giá trị gia tăng sẽ bị xếp vào mức đánh giá thấp nhất, một tiêu chí áp dụng công bằng cho cả nội dung con người viết cẩu thả.
Nói cách khác thì cấu trúc câu rập khuôn của AI không phải là "bản án tử" trực tiếp cho SEO, nhưng nó là một tín hiệu gián tiếp mạnh mẽ cho thấy nội dung có thể thiếu sự can thiệp biên tập thực chất, và chính khoảng trống đó là nơi các thuật toán xếp hạng hiện đại, được huấn luyện để nhận diện "tính giống nhau" và sự thiếu nỗ lực biên tập ở quy mô lớn, bắt đầu can thiệp. Đây chính là lý do tại sao việc dùng một AI thứ hai để "tẩy" dấu vết rập khuôn không đơn thuần là một mẹo lách luật xếp hạng, mà thực chất là một bước nâng cấp chất lượng thực sự - biến một bản nháp generic thành một bài viết có dấu ấn biên tập rõ ràng.
Ma trận kỹ thuật: Cách một AI kiểm tra và "thanh trừng" lỗi của một AI khác
Khi đóng vai trò biên tập viên thuật toán, một mô hình AI thứ hai thường vận hành qua ba lớp lọc chính, mỗi lớp giải quyết một loại lỗ hổng riêng biệt đã được phân tích ở phần trên.
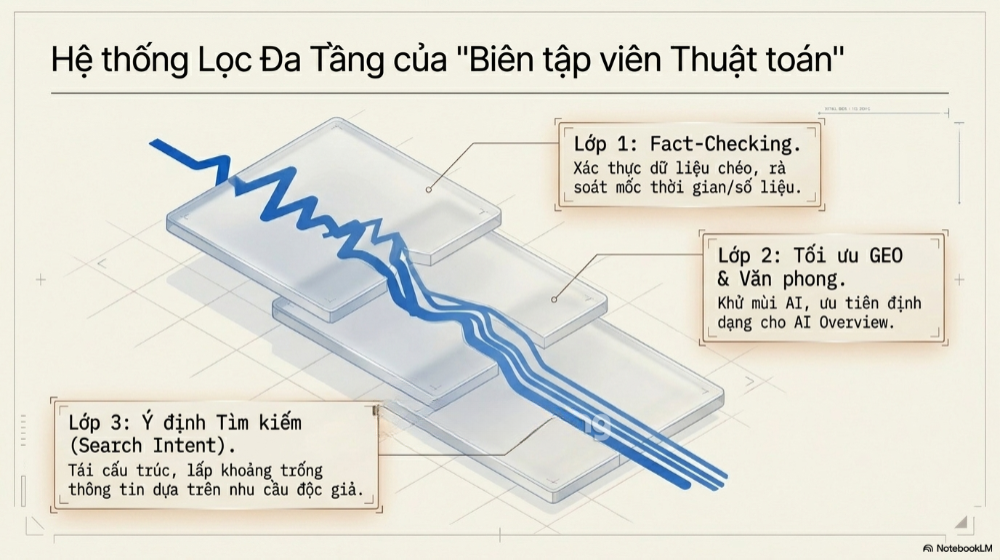
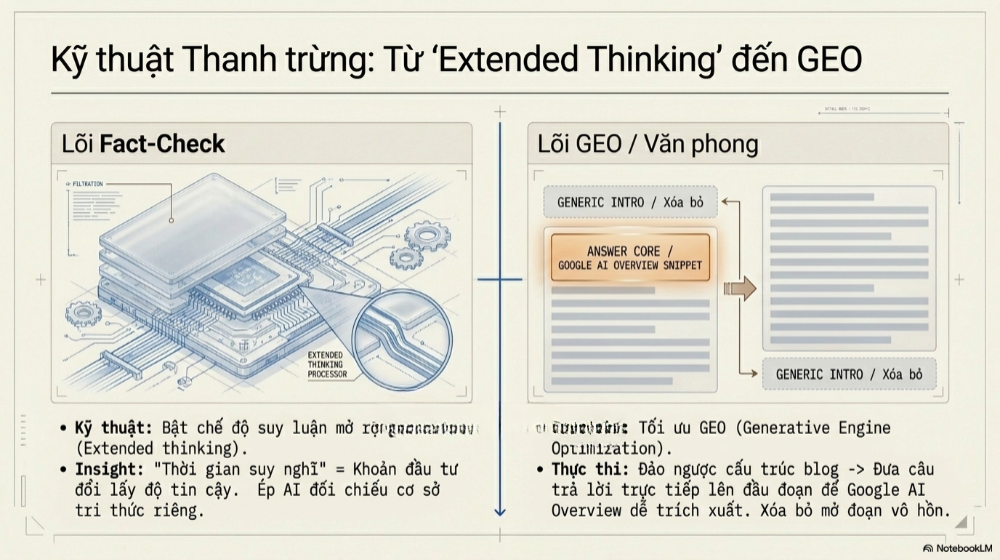
Bộ lọc Fact-Checking (Xác thực dữ liệu chéo)
Ở lớp này, AI thứ hai được giao nhiệm vụ rà soát từng mốc thời gian, từng con số thống kê, từng tên riêng xuất hiện trong bản dự thảo, đối chiếu với dữ liệu cập nhật theo thời gian thực thông qua khả năng truy cập web hoặc cơ sở tri thức riêng của nó – một năng lực mà mô hình đầu tiên có thể không có hoặc không được kích hoạt trong quá trình tạo bản nháp.
Cơ chế này hoạt động hiệu quả nhất khi hai mô hình có "thế mạnh lệch nhau": mô hình tạo nội dung tối ưu cho tốc độ và sự trôi chảy, còn mô hình kiểm định được tối ưu cho độ chính xác và khả năng truy xuất nguồn gốc. Các nghiên cứu benchmark gần đây cho thấy việc bật chế độ suy luận mở rộng (extended thinking) ở mô hình kiểm định có thể kéo giảm tỷ lệ sai sót xuống gần một nửa so với khi không bật, một minh chứng cho thấy "thời gian suy nghĩ" của AI thứ hai chính là khoản đầu tư đổi lấy độ tin cậy.
Bộ lọc Nhận diện văn phong & Tối ưu hóa GEO
Đây là lớp lọc giải quyết trực tiếp vấn đề "AI Footprint" đã nêu ở phần trước. AI thứ hai được huấn luyện hoặc được hướng dẫn (qua prompt) để quét tìm các cụm từ sáo rỗng đặc trưng của văn bản máy – những cách mở đoạn an toàn nhưng vô hồn, những cách chuyển ý mang tính công thức, hay những lối kết luận khẳng định tầm quan trọng một cách chung chung không gắn với dữ kiện cụ thể nào. Khi phát hiện, AI sẽ viết lại đoạn văn đó bằng cấu trúc câu tự nhiên hơn, gần với cách một người viết có kinh nghiệm thực sẽ diễn đạt – ngắn gọn hơn, cụ thể hơn, ít tính trang trọng giả tạo hơn.
Song song với việc "khử mùi AI", lớp lọc này còn đảm nhiệm việc tối ưu hóa cho GEO (Generative Engine Optimization) – định dạng lại nội dung sao cho các công cụ tìm kiếm tạo sinh như AI Overview của Google có thể dễ dàng trích xuất, tóm tắt và trình bày lại nội dung trong câu trả lời của chính chúng. Điều này thường đòi hỏi việc đặt câu trả lời trực tiếp ngay đầu mỗi đoạn, trước khi đi vào giải thích chi tiết – một kỹ thuật viết hoàn toàn khác với cách viết bài blog truyền thống vốn quen dẫn dắt từ từ.
Bộ lọc Cấu trúc ngữ cảnh và Ý định tìm kiếm
Lớp lọc thứ ba đánh giá xem nội dung, dù đã chính xác về dữ kiện và tự nhiên về văn phong, có thực sự trả lời đúng điều người tìm kiếm mong muốn hay không. AI kiểm định ở lớp này thường được giao vai trò "đóng giả" người đọc thực, đặt câu hỏi ngược lại: nếu một người gõ truy vấn này vào công cụ tìm kiếm, họ đang thực sự cần thông tin gì, ở mức độ chi tiết nào, theo định dạng nào (danh sách, bảng so sánh, hướng dẫn từng bước)? Từ đó, AI đề xuất việc tái cấu trúc lại toàn bộ thứ tự các phần, bổ sung những khoảng trống thông tin mà bản dự thảo đầu tiên đã bỏ sót.
Case Study & Quy trình phối hợp (Workflow) thực tế giữa các Model
Trong thực tế vận hành tại nhiều agency và đội ngũ sản xuất nội dung độc lập năm 2026, một quy trình phối hợp bốn bước đã trở thành khuôn mẫu phổ biến, dù tên mô hình cụ thể có thể thay đổi tùy ngân sách và mục tiêu của từng nhóm:
| Bước | Vai trò | Mô hình thường dùng | Nhiệm vụ cụ thể |
|---|---|---|---|
| 1 | Thu thập dữ liệu sạch | Perplexity, Sonar | Tìm kiếm, tổng hợp dữ liệu, số liệu cập nhật theo thời gian thực kèm nguồn tham chiếu |
| 2 | Dựng khung & viết nội dung | ChatGPT (GPT) | Tạo dàn ý, viết bản dự thảo đầy đủ dựa trên dữ liệu đã thu thập |
| 3 | Biên tập văn phong & fact-check | Claude | Rà soát lỗi sai dữ kiện, viết lại đoạn rập khuôn, tinh chỉnh văn phong tự nhiên |
| 4 | Tối ưu kỹ thuật ngầm | Bộ lọc Schema/SEO chuyên dụng | Chuẩn hóa cấu trúc heading, đánh dấu schema, kiểm tra mật độ từ khóa |
Điểm đáng chú ý trong mô hình này là sự phân công lao động dựa trên đúng "tính cách" của từng mô hình, hơn là việc cố ép một mô hình duy nhất làm tất cả. Các mô hình thiên về tìm kiếm thực tế thường mạnh ở việc đào dữ liệu mới nhưng có thể yếu hơn về khả năng tổ chức luận điểm logic dài hơi; các mô hình thiên về sáng tạo nội dung lại mạnh ở việc dựng cấu trúc bài bản nhưng dễ rơi vào lối viết "an toàn", rập khuôn; còn các mô hình thiên về suy luận và xử lý ngôn ngữ tinh tế lại phát huy tốt nhất ở vai trò biên tập – đọc kỹ, bắt lỗi logic, và "thổi hồn" lại cho câu chữ.
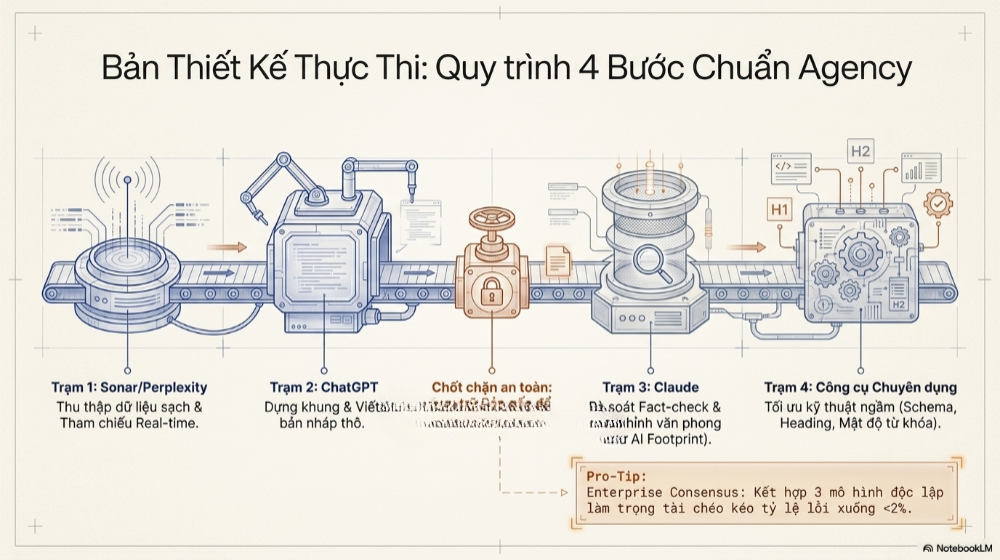
Một số đội ngũ kỹ thuật cao hơn còn bổ sung thêm một vòng kiểm định chéo thứ năm: dùng một mô hình thứ ba hoàn toàn độc lập để "trọng tài" khi hai mô hình đầu đưa ra kết luận khác nhau về một dữ kiện gây tranh cãi – một cơ chế tương tự nguyên tắc đồng thuận đa số (multi-model consensus) đang được áp dụng trong các hệ thống AI doanh nghiệp đòi hỏi độ chính xác cực cao, nơi việc kết hợp từ ba mô hình độc lập trở lên có thể kéo tỷ lệ sai sót thông tin xuống dưới ngưỡng 2%.
Góc nhìn phản biện: Vòng lặp AI-on-AI có đang làm xói mòn tính nguyên bản của con người?
Bức tranh trên nghe có vẻ như một dây chuyền sản xuất hoàn hảo – nhưng chính sự hoàn hảo đó lại là nguồn gốc của một câu hỏi gai góc hơn: liệu một bài viết được sinh ra, kiểm tra, và tinh chỉnh hoàn toàn bởi các mô hình AI, dù không còn một lỗi sai dữ kiện hay một câu rập khuôn nào, có thực sự còn mang "linh hồn" của một bài viết do con người tạo ra không?
Đây không phải là câu hỏi cảm tính thuần túy. Nó chạm trực tiếp vào khái niệm E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness) – bốn yếu tố mà các công cụ tìm kiếm hiện đại dùng để đánh giá độ tin cậy của nội dung. Trong đó, chữ "E" đầu tiên – Experience, tức trải nghiệm thực tế, là thứ mà không một AI, dù được một AI khác kiểm tra kỹ lưỡng đến đâu, có thể tự tạo ra từ con số không. Một bài viết về việc leo núi Everest có thể được hai AI phối hợp viết ra hoàn hảo về cấu trúc, chính xác về số liệu độ cao và nhiệt độ, nhưng nó sẽ không bao giờ chứa đựng được cảm giác lạnh cắt da thực sự, mùi vị của bình oxy, hay nỗi sợ hãi cụ thể của một người đã từng đứng ở đó.

Nguy cơ thực sự của vòng lặp AI-on-AI, do đó, không nằm ở việc nó tạo ra nội dung sai - ngược lại, nó có thể tạo ra nội dung cực kỳ chính xác về dữ kiện và mượt mà về câu chữ. Nguy cơ nằm ở việc nó có thể tạo ra một dạng nội dung mà giới làm nghề gọi là "vô hồn nhưng hoàn hảo" – đúng ngữ pháp, đủ dữ liệu, không một câu sáo rỗng nào còn sót lại, nhưng hoàn toàn thiếu vắng một góc nhìn cá nhân, một trải nghiệm không thể giả lập, hay một quan điểm dám gây tranh cãi.
Chính vì vậy, vai trò của con người trong vòng lặp này (Human-in-the-loop) không hề bị thu nhỏ lại – nó dịch chuyển sang một vị trí khác, mang tính quyết định hơn. Con người không còn cần phải tự tay sửa từng lỗi chính tả hay kiểm tra từng con số (việc đó các AI đã làm tốt với nhau), nhưng con người trở thành người duy nhất có thể trả lời câu hỏi: bài viết này có nói ra được điều gì mà chưa ai từng nói, có mang theo một trải nghiệm hay một góc nhìn không thể thay thế bằng dữ liệu huấn luyện hay không? Nhiệm vụ biên tập của con người, nói cách khác, đã dịch chuyển từ việc "bắt lỗi câu chữ" lên một tầng cao hơn: "thẩm định linh hồn".
Kết Luận
Khi các AI ngày càng giỏi trong việc tự sửa lỗi cho nhau, có một nghịch lý thú vị đang dần hiện rõ: chất lượng kỹ thuật của nội dung (độ chính xác, sự trôi chảy, cấu trúc chuẩn SEO) sẽ ngày càng tiến gần đến một mức sàn chung mà hầu như ai cũng đạt được. Bởi ai cũng có thể dùng cùng một combo mô hình để kiểm tra chéo cho nhau. Khi "sàn chất lượng kỹ thuật" được nâng lên đồng loạt cho toàn ngành, yếu tố thực sự tạo ra khác biệt cạnh tranh sẽ không còn là việc "viết đúng" hay "viết sạch" nữa, mà là việc viết ra được điều mà cỗ máy kiểm định tinh vi nhất cũng không thể tự nghĩ ra: một trải nghiệm thật, một dữ liệu độc quyền, một quan điểm dám đứng về một phía.
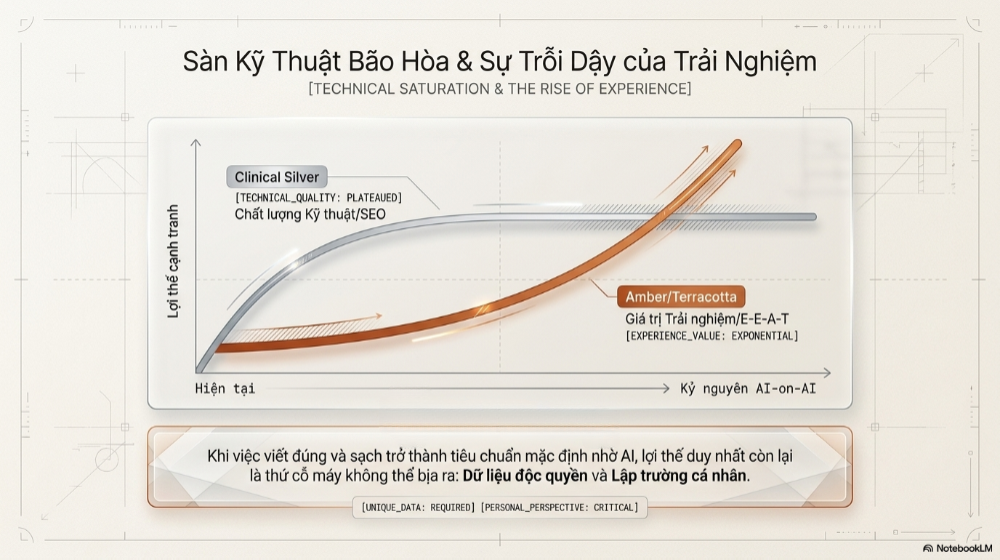
Trong vài năm tới, có thể dự đoán một sự phân tách rõ rệt hơn của thị trường nội dung số: một mảng lớn nội dung mang tính thông tin thuần túy, được sản xuất và kiểm định gần như hoàn toàn tự động, đạt chuẩn về độ chính xác nhưng cạnh tranh khốc liệt vì ai cũng làm được; và một mảng nhỏ hơn nhưng giá trị cao hơn nhiều, nơi con người vẫn đứng ở vị trí trung tâm, không phải để sửa lỗi câu chữ, mà để cung cấp chính nguyên liệu mà không một mô hình AI nào, dù được kiểm tra chéo bao nhiêu lần, có thể tự bịa ra: kinh nghiệm sống thực, dữ liệu độc quyền thu thập trực tiếp, và một lập trường cá nhân đủ can đảm để không "trung tính hóa" mọi thứ.

Kỷ nguyên của những biên tập viên thuật toán, vì thế, không phải là sự cáo chung của vai trò con người trong sáng tạo nội dung, nó là một cuộc tái phân vai. Máy lo phần đúng. Người lo phần thật.
FAQ - Hỏi Đáp Nhanh
Nên dùng kết hợp những model AI nào tốt nhất để kiểm tra chéo lỗi?
Mô hình hiệu quả nhất hiện nay là kết hợp một mô hình mạnh về tìm kiếm thời gian thực (như Perplexity Sonar) cho khâu thu thập dữ liệu, với một mô hình mạnh về suy luận và xử lý ngôn ngữ tinh tế (như Claude hoặc Gemini) cho khâu biên tập, fact-check và khử văn phong rập khuôn. Việc kết hợp hai mô hình có "thế mạnh lệch nhau" luôn hiệu quả hơn dùng hai phiên bản cùng một mô hình để kiểm tra lẫn nhau, vì chúng dễ mắc cùng một loại lỗi.
Làm sao để tránh việc AI thứ hai tự động phá hỏng ý tưởng cốt lõi của AI thứ nhất?
Cách an toàn nhất là luôn ra lệnh rõ ràng cho AI kiểm định về phạm vi can thiệp được phép – ví dụ chỉ cho phép sửa văn phong và fact-check, tuyệt đối không cho phép thay đổi cấu trúc luận điểm hay quan điểm chính của bài viết. Việc giữ lại một bản gốc trước khi đưa qua AI thứ hai cũng giúp con người dễ dàng so sánh và khôi phục nếu phát hiện ý tưởng cốt lõi bị làm loãng đi trong quá trình "biên tập".

AI kiểm tra AI có thực sự giúp bài viết lên hạng tốt hơn trên Google không?
Không có cơ chế xếp hạng trực tiếp nào ưu ái nội dung "đã được AI khác kiểm tra". Lợi ích thực sự đến gián tiếp: việc loại bỏ lỗi sai dữ kiện và cấu trúc câu rập khuôn giúp nội dung trông tự nhiên hơn, đáng tin hơn – những yếu tố nằm trong bộ tiêu chí E-E-A-T mà các công cụ tìm kiếm đánh giá. Nội dung vẫn cần một lớp giá trị gia tăng thực sự từ con người để cạnh tranh được trong dài hạn.
Quy trình AI-on-AI có phù hợp với mọi loại nội dung không? Phù hợp nhất với nội dung mang tính thông tin, hướng dẫn, hoặc tổng hợp dữ liệu – nơi độ chính xác là yếu tố quan trọng hàng đầu. Với nội dung đòi hỏi giọng văn cá nhân mạnh, ý kiến riêng biệt, hoặc kể chuyện trải nghiệm thật, vai trò của AI kiểm định nên giới hạn ở việc rà lỗi kỹ thuật, để tránh việc lớp biên tập tự động vô tình "trung tính hóa" mất chất giọng riêng của người viết gốc.