Việc lựa chọn giữa Gemma 4 và Qwen cho kiểm thử xâm nhập bằng AI thực chất không phải là vấn đề về hiệu năng. Đó là vấn đề về quy trình làm việc. Một hệ thống kiểm thử xâm nhập không thành công chỉ vì mô hình có vẻ sắc bén hơn trong giao tiếp. Nó thành công vì có thể duy trì trạng thái xuyên suốt các bằng chứng phức tạp, đề xuất các hành động tiếp theo hữu ích, giữ đúng phạm vi và tránh biến việc sử dụng công cụ thành một bề mặt tấn công mới.
Đó chính là lý do tại sao bài báo của PentestGPT vẫn còn quan trọng: Phát hiện cốt lõi của nó không phải là các mô hình ngôn ngữ lớn (LLM) có thể thay thế hoàn toàn người kiểm thử, mà là chúng có thể hỗ trợ một cách có ý nghĩa trong các nhiệm vụ phụ cụ thể, trong khi quy trình làm việc tổng thể vẫn cần thiết kế theo mô-đun để giảm thiểu mất ngữ cảnh và duy trì hình thức của một cuộc kiểm thử.
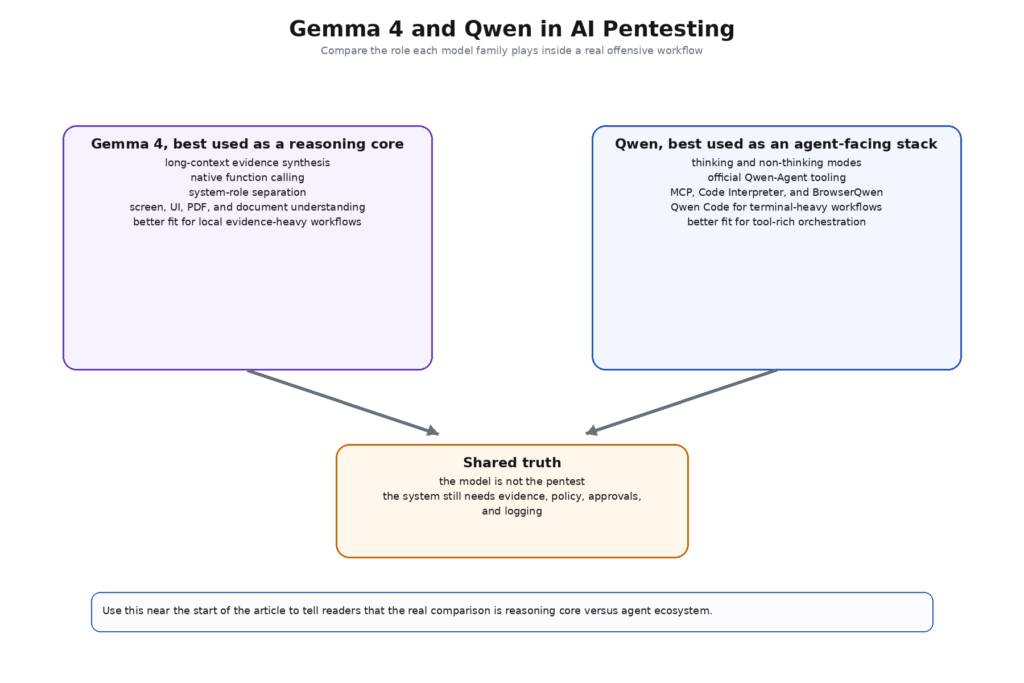
Gemma 4 và Qwen không còn giống như những sản phẩm thay thế trực tiếp mà trở thành hai cách khác nhau để xây dựng phần giữa của một hệ thống bảo mật tấn công. Sự khác biệt đó rất quan trọng đối với người mua, người xây dựng và các nhà nghiên cứu.
Gemma 4 so với Qwen cho kiểm thử xâm nhập AI
Hãy so sánh Gemma 4 và Qwen trong kiểm thử thâm nhập AI một cách công bằng!
Sai lầm đầu tiên trong lĩnh vực này là so sánh mô hình cơ bản của một nhà cung cấp với toàn bộ hệ sinh thái của nhà cung cấp khác. Để có một cuộc thảo luận công bằng, sự so sánh mô hình rõ ràng nhất là Gemma 4 31B với Qwen3 32B, với Qwen3 30B-A3B là lựa chọn thay thế theo kiểu MoE mở, thiên về agent hơn trong cùng một dòng sản phẩm. Card mô hình Gemma 4 của Google liệt kê mô hình 31B dense và mô hình MoE A4B 26B, cả hai đều có ngữ cảnh 256K. Kho lưu trữ chính thức của Qwen3 liệt kê các biến thể 32B dense cộng với 30B-A3B và 235B-A22B MoE, và mô tả dòng sản phẩm này hỗ trợ chuyển đổi liền mạch giữa chế độ tư duy và không tư duy.
Sai lầm thứ hai là che giấu tính đa phương thức bên trong sự so sánh mô hình ngôn ngữ. Gemma 4 31B hỗ trợ nhập văn bản và hình ảnh một cách tự nhiên như một phần của cùng một họ mô hình, và card mô hình của Google liệt kê rõ ràng việc phân tích tài liệu và PDF, hiểu màn hình và giao diện người dùng, OCR và hiểu biểu đồ là những khả năng cốt lõi. Qwen hoàn toàn có thể cạnh tranh trong công việc đa phương thức, nhưng cách chính thức để làm điều đó thường không phải là Qwen3 thông thường.
Đó là các mô hình đa phương thức thuộc lớp Qwen3-VL hoặc Qwen3.5. Kho lưu trữ của Qwen3-VL mô tả nó là mô hình ngôn ngữ-hình ảnh mạnh nhất trong chuỗi Qwen cho đến nay, với định hướng agent hình ảnh, ngữ cảnh 256K gốc và mở rộng ngữ cảnh 1M thông qua YaRN. Điều đó có nghĩa là câu trả lời "Gemma 4 so với Qwen" thay đổi tùy thuộc vào việc bạn đang nói đến các mô hình ngôn ngữ Qwen3 hay ngăn xếp agent và đa phương thức Qwen rộng hơn.
Sai lầm thứ ba là giả định rằng kiểm thử xâm nhập nên quan tâm nhất đến các bảng benchmark của nhà cung cấp. Điều đó không đúng. Các bảng benchmark của nhà cung cấp rất tốt trong việc cho bạn biết nhà cung cấp muốn họ mô hình của họ được hiểu như thế nào. Họ không giỏi trong việc cho bạn biết mô hình sẽ hoạt động như thế nào khi được cung cấp ảnh chụp màn hình từ cổng quản trị, dấu vết trình duyệt được xác thực một phần, một số tuyến đường được trích xuất bằng JavaScript, ma trận khác biệt vai trò và yêu cầu không được vượt quá phạm vi hoặc kích hoạt các hành động phá hoại.
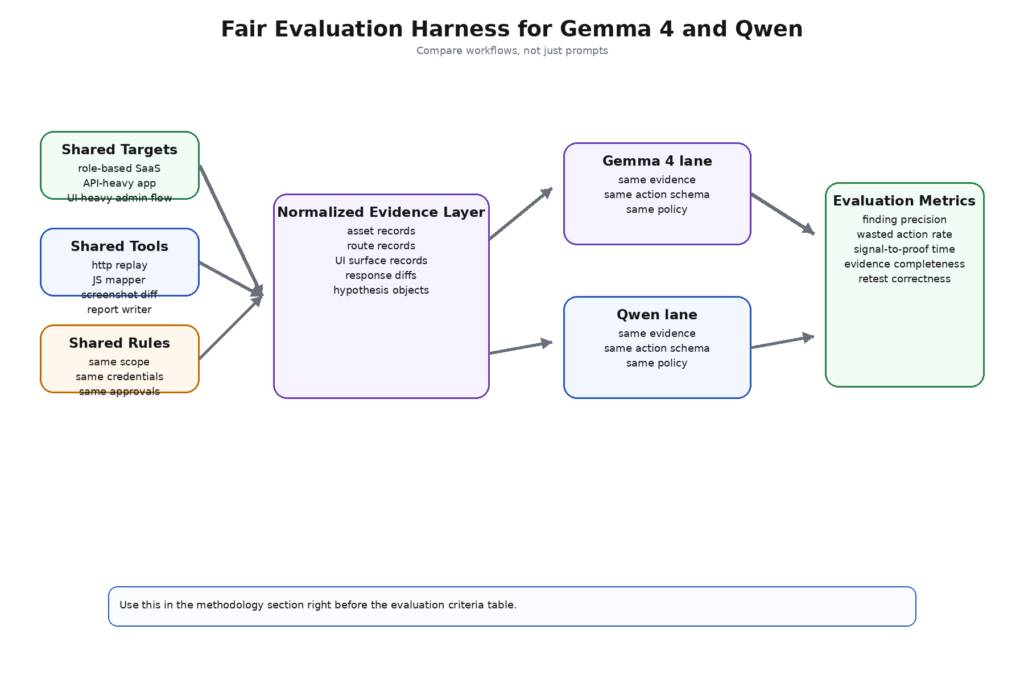
Kiểm thử xâm nhập là một vấn đề hệ thống. Mô hình rất quan trọng, nhưng chỉ bên trong mặt phẳng điều khiển bao quanh nó. Đó là bài học mà các bài viết về AI kiểm thử xâm nhập công khai luôn quay trở lại: Câu hỏi bền vững không phải là "mô hình nào giải thích đầu ra của nmap tốt nhất", mà là "hệ thống nào có thể chuyển từ tín hiệu thô sang kết quả được xác minh mà không mất kiểm soát".
Do đó, một sự so sánh công bằng có 4 lớp. Đầu tiên là chính mô hình: Độ dài ngữ cảnh, chế độ suy luận, loại đầu vào và hành vi suy luận cốt lõi. Thứ hai là bề mặt công cụ: Gọi hàm, hỗ trợ trình phân tích cú pháp, agent framework và tích hợp terminal. Thứ ba là bề mặt rào chắn: Mức độ dễ dàng để giữ cho chính sách, phạm vi và thực thi tách biệt khỏi mô hình. Thứ tư là bề mặt vận hành: Mức độ dễ dàng triển khai mô hình và các công cụ của nó cục bộ, quản trị, kiểm toán và tránh khỏi đường dẫn mạng sai. Khi so sánh Gemma 4 và Qwen ở 4 lớp này, sự lựa chọn trở nên ít mang tính lý thuyết hơn và thực tế hơn nhiều.
Đánh giá Gemma và Qwen
Bề mặt khả năng chính thức quan trọng trong kiểm thử xâm nhập AI
Trước khi bàn về mô hình nào tốt hơn, điều đáng xem xét là những gì Google và Qwen thực sự công khai trong tài liệu, bởi vì những kết luận an toàn nhất thường đến từ những phần nhàm chán của tài liệu, chứ không phải từ sự cường điệu vào ngày ra mắt. Tài liệu Gemma 4 của Google cho biết mô hình 31B Dense và mô hình 26B A4B trung bình hỗ trợ ngữ cảnh 256K, tư duy cấu hình, đầu vào đa phương thức, gọi hàm và hỗ trợ gốc cho vai trò hệ thống.
Google cũng ghi lại yêu cầu bộ nhớ suy luận gần đúng của mô hình 31B là 58,3 GB trong BF16, 30,4 GB trong 8-bit và 17,4 GB trong Q4_0, đồng thời cảnh báo rằng ngữ cảnh và chi phí phần mềm là thêm. Kho lưu trữ chính thức Qwen3 của Qwen ghi lại các mô hình dense và MoE từ 0,6B đến 32B, 30B-A3B và 235B-A22B, cộng với việc chuyển đổi giữa chế độ tư duy và không tư duy, và xử lý ngữ cảnh dài mà kho lưu trữ mô tả là 256K, có thể mở rộng lên đến 1 triệu token.
| Khả năng | Gemma 4 | Qwen | Tại sao điều này lại quan trọng trong kiểm thử xâm nhập AI? |
|---|---|---|---|
| Cửa sổ ngữ cảnh cốt lõi | Lên đến 256K trên 31B và 26B A4B | Khả năng hiểu ngữ cảnh dài 256K, có thể mở rộng lên 1M trong ngôn ngữ Qwen3 repo | Các cuộc điều tra kéo dài cần nhiều thời gian hơn cho việc trinh sát, thu thập dấu vết, ghi chú và phân tích sự khác biệt về vai trò |
| Chế độ tư duy | Chế độ tư duy có thể cấu hình trên Gemma 4 | Chế độ tư duy và không tư duy, với các nút điều khiển chuyển đổi rõ ràng | Quy trình kiểm thử xâm nhập xen kẽ giữa phân tích chuyên sâu và các thao tác vận hành đơn giản hơn |
| Chức năng và cách sử dụng công cụ | Gọi hàm gốc, cộng thêm cảnh báo rõ ràng của Google rằng việc thực thi phải được xác thực từ bên ngoài | Qwen3 nhấn mạnh việc sử dụng công cụ, còn Qwen-Agent bổ sung khả năng gọi và phân tích cú pháp công cụ đa bước một cách tự nhiên | Việc sử dụng công cụ chỉ hữu ích khi nó được cấu trúc và kiểm soát chặt chẽ |
| Đa phương thức | Gemma 4 31B hỗ trợ nhập văn bản và hình ảnh trong cùng một dòng sản phẩm, bao gồm cả khả năng hiểu giao diện người dùng và định dạng PDF | Câu chuyện đa phương thức của Qwen chủ yếu nằm trong Qwen3-VL và các dòng sản phẩm liên quan | Việc kiểm thử ứng dụng dựa nhiều vào ảnh chụp màn hình đã thay đổi ý nghĩa của cụm từ “mô hình tốt hơn” |
| Agent framework | Hiện chưa có bất kỳ agent framework ưu tiên Gemma chính thức nào có thể so sánh được với Qwen-Agent | Qwen-Agent chính thức hỗ trợ MCP, Code Interpreter, BrowserQwen và các công cụ tùy chỉnh | Các công cụ chính thức mạnh mẽ hơn có thể đẩy nhanh quá trình tạo mẫu agentic |
| Terminal agent | Việc gọi hàm đã tồn tại, nhưng công cụ terminal không phải là câu chuyện chính được công chúng quan tâm | Qwen Code là một agent mã nguồn mở ưu tiên terminal dành cho các mô hình Qwen | Việc xem xét kho lưu trữ, viết script và các quy trình làm việc sử dụng nhiều công cụ thường diễn ra trong terminal |
Gemma 4 phù hợp một cách tự nhiên với suy luận kiểm thử xâm nhập cục bộ
Điểm mạnh nhất của Gemma 4 trong bảo mật tấn công không phải vì nó là mô hình mở mang tính agentic nhất trên lý thuyết. Mà chính là tài liệu của Google giúp việc sử dụng nó như một lõi suy luận cục bộ trở nên dễ dàng bất thường mà không cần giả vờ rằng bản thân mô hình phải sở hữu khả năng thực thi.
Tài liệu của Google mô tả chi tiết ngữ cảnh dài, hỗ trợ vai trò hệ thống, gọi hàm và một tập hợp các khả năng đa phương thức, trùng khớp một cách đáng ngờ với bằng chứng kiểm thử xâm nhập thực tế: phân tích tài liệu và PDF, hiểu giao diện người dùng và màn hình, nhận dạng ký tự quang học (OCR) và hiểu biểu đồ. Hướng dẫn gọi hàm của Google cũng nêu rõ ràng rào cản quan trọng nhất: mô hình Gemma không thể tự thực thi code và bất kỳ code nào được tạo ra đều phải được chạy và xác thực bởi ứng dụng với các biện pháp bảo vệ được thiết lập sẵn. Đó chính xác là mô hình tư duy đúng đắn cho bảo mật tấn công.
Gemma 4 cũng được hưởng lợi từ một câu chuyện rõ ràng hơn về kiểm soát cục bộ. Tài liệu mô hình của Google đặt các mô hình 31B và 26B A4B vào lãnh địa GPU dành cho người tiêu dùng và máy trạm, trong khi các mô hình nhỏ hơn được mô tả rõ ràng là thân thiện với thiết bị.
Còn một lợi thế tinh tế khác trong cấu trúc prompt và vai trò của Gemma 4. Tài liệu định dạng prompt của Google hiển thị các token điều khiển rõ ràng cho những lượt hệ thống, người dùng và mô hình, cùng với các token điều khiển riêng biệt cho agent và suy luận. Điều này rất quan trọng trong một kiến trúc kiểm thử xâm nhập được bảo vệ vì các quy tắc về chính sách, phạm vi và phê duyệt không nên nằm chung trong cùng một mớ hỗn độn văn bản với bằng chứng mục tiêu.
Kết quả thực tế là Gemma 4 giống như một họ mô hình nằm sau một lớp chuẩn hóa.
Qwen phù hợp tự nhiên với một hệ sinh thái agent nặng về công cụ
Điểm mạnh nhất của Qwen trong kiểm thử thâm nhập AI nằm ở một khía cạnh khác. Nếu Gemma 4 mang lại cảm giác như một lõi suy luận cục bộ gọn gàng, thì Qwen lại giống như một hệ sinh thái đã quyết định rằng việc sử dụng công cụ là một phần của câu chuyện sản phẩm. Kho lưu trữ Qwen3 mô tả dòng sản phẩm này hỗ trợ chuyển đổi liền mạch giữa chế độ tư duy và không tư duy, các mô hình Dense và MoE, khả năng hiểu ngữ cảnh dài 256K có thể mở rộng lên 1 triệu token, và chuyên môn về khả năng của agent với tích hợp công cụ bên ngoài ở cả chế độ tư duy và không tư duy. Đó đã là một lập trường hướng đến agent rõ ràng hơn so với những gì Google nói về Gemma 4.
Tuy nhiên, có một vấn đề quan trọng hơn trong bảo mật so với các công cụ phát triển thông thường. Bề mặt công cụ càng phong phú, vấn đề ranh giới càng trở nên khó khăn hơn. Qwen-Agent cung cấp rõ ràng một công cụ code_interpreter thực thi code Python. Nó hỗ trợ rõ ràng việc tích hợp MCP. Nó hỗ trợ rõ ràng các công cụ bên ngoài và những công cụ tùy chỉnh. Sức mạnh đó rất hữu ích. Nó cũng nhắc nhở rằng một hệ thống kiểm thử xâm nhập AI tập trung vào Qwen có khả năng tích lũy bề mặt thực thi rộng hơn nhanh hơn so với một hệ thống suy luận tập trung vào Gemma. Nói cách khác, điều khiến Qwen dễ áp dụng hơn cho tự động hóa agent cũng chính là điều khiến việc quản trị trở nên cấp bách hơn.
Bằng chứng đa phương thức thay đổi sự so sánh nhiều hơn hầu hết các bài đánh giá mô hình thừa nhận
Nhiều bài so sánh mô hình vẫn coi tính đa phương thức là một tính năng dành cho người dùng cuối. Trong kiểm thử xâm nhập bằng AI, điều đó không đúng. Quy trình làm việc dựa trên ảnh chụp màn hình và tài liệu rất phổ biến, đó thường chính là nơi mà sự hỗ trợ của LLM trở nên hữu ích.
Hãy nghĩ về bằng chứng thực tế mà một nhóm tấn công xử lý: Ảnh chụp màn hình của cổng quản trị, bảng điều khiển thanh toán, bảng điều khiển nội bộ, hàng đợi kiểm duyệt, màn hình xuất, giao diện người dùng flag tính năng, luồng dành riêng cho vai trò, PDF kiến trúc và các tài liệu hỗ trợ hoặc triển khai dài. Một mô hình có thể suy luận trên các đầu vào đó sẽ trực tiếp thay đổi ý nghĩa của "kiểm thử xâm nhập bằng AI".
Đây là lý do Gemma 4 trở nên đặc biệt hấp dẫn. Card mô hình của Google liệt kê rõ ràng các khả năng hiểu hình ảnh cốt lõi như phân tích tài liệu và PDF, hiểu màn hình và giao diện người dùng, nhận dạng ký tự quang học (OCR) và xử lý hình ảnh độ phân giải thay đổi. Điều đó có nghĩa là cùng một nhóm mô hình xử lý suy luận văn bản dài và gọi hàm cũng có thể xử lý ảnh chụp màn hình và tài liệu trong cùng một luồng mô hình.
Đối với các nhóm xây dựng quy trình làm việc tập trung vào bằng chứng cục bộ, đó là một sự đơn giản hóa lớn. Bạn không cần một nhóm mô hình đa phương thức riêng biệt chỉ để phân loại xem ảnh chụp màn hình trông giống như bảng điều khiển xuất nội bộ, chế độ xem kiểm duyệt chỉ dành cho nhân viên hay bảng điều khiển người dùng thông thường với những khác biệt về hình thức.
Qwen hoàn toàn có thể giải quyết thách thức này, nhưng câu trả lời thường đến từ một dòng mô hình khác. Kho lưu trữ của Qwen3-VL mô tả đầy đủ câu chuyện về agent trực quan, bao gồm hoạt động GUI, khả năng tương tác agent mạnh mẽ hơn, ngữ cảnh 256K gốc và các tính năng phân tích tài liệu.
Nếu một nhóm sẵn sàng mở rộng khía cạnh "Qwen" của sự so sánh từ các mô hình ngôn ngữ Qwen3 sang Qwen3-VL cộng với Qwen-Agent, thì khoảng cách đa phương thức sẽ thu hẹp đáng kể và có thể biến mất đối với một số quy trình làm việc. Nhưng đó lại trở thành một quyết định hệ thống khác so với việc so sánh “Gemma 4 31B với Qwen3 32B”. Nó trở thành “một họ mà tính đa phương thức đã là một phần của sự so sánh” so với “một họ rộng hơn mà tính đa phương thức nằm trong một nhánh riêng biệt liền kề”. Đó là một sự khác biệt kiến trúc có ý nghĩa.
Kết luận: Không có tùy chọn chiến thắng hoàn toàn!
Nếu câu hỏi là mô hình nào dễ sử dụng làm lõi suy luận cục bộ được bảo vệ cho kiểm thử xâm nhập AI hơn, thì câu trả lời là Gemma 4, đặc biệt là Gemma 4 31B. Bộ tính năng chính thức phù hợp một cách bất thường với những gì quy trình tấn công nặng về bằng chứng thực sự cần: Ngữ cảnh dài, gọi hàm gốc, hỗ trợ vai trò hệ thống, hiểu giao diện người dùng và PDF, cảnh báo rõ ràng từ nhà cung cấp rằng việc thực thi phải nằm ngoài mô hình và bên trong logic ứng dụng đã được xác thực. Đó là một hình thức tốt cho công việc bảo mật.
Nếu câu hỏi là mô hình nào dễ sử dụng hơn làm ngăn xếp agent mở rộng hơn với các công cụ chính thức để gọi hàm, MCP, thực thi code, quy trình làm việc terminal và hỗ trợ trình duyệt, thì câu trả lời là Qwen. Sự kết hợp của Qwen3, Qwen-Agent và Qwen Code cung cấp cho các nhà phát triển nhiều thành phần chính thức hơn cho việc thực thi agent so với Gemma hiện tại. Đó là một điểm mạnh thực sự, chứ không phải chỉ là hình thức bên ngoài. Điều đó cũng có nghĩa là nhóm phải coi việc lạm dụng công cụ, thiết kế ranh giới thực thi và tăng cường bảo mật dịch vụ cục bộ là những hạng mục công việc ưu tiên hàng đầu chứ không phải là những việc cần hoàn thiện sau này.
Nếu câu hỏi là mô hình nào tốt hơn cho việc kiểm thử xâm nhập đa phương thức với ảnh chụp màn hình và bằng chứng tài liệu, thì câu trả lời sẽ mang tính tương đối. Gemma 4 đơn giản hóa vấn đề nếu bạn muốn một dòng sản phẩm đã bao gồm những khả năng đó. Qwen hoàn toàn có thể cạnh tranh nếu so sánh mở rộng đến Qwen3-VL, nhưng đó là một lựa chọn hệ thống khác so với Qwen3 cộng với công cụ agent. Câu trả lời trung thực không phải là “Gemma thắng” hay “Qwen thắng”, mà là “trước tiên hãy quyết định xem bạn đang chọn một mô hình, một hệ sinh thái agent hay một môi trường làm việc bảo mật đa phương thức”.
Đó mới là phán quyết thực sự. Gemma 4 là lựa chọn tối ưu hơn cho các nhóm muốn có một mô hình cục bộ được quản lý để suy nghĩ, so sánh, xếp hạng và giải thích. Qwen là lựa chọn tối ưu hơn cho các nhóm muốn có bề mặt agent chính thức rộng hơn và sẵn sàng chấp nhận những rủi ro bảo mật cao hơn đi kèm với nó. Trong lĩnh vực kiểm thử xâm nhập bằng trí tuệ nhân tạo, đó thường là kiểu tùy chọn chiến thắng trung thực nhất mà bạn có thể nghĩ đến.